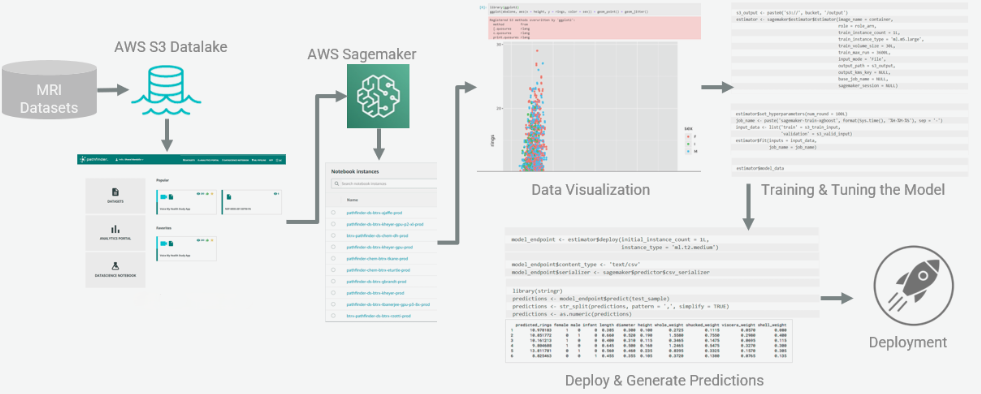
Pipeline for Data Engineering & Machine Learning
Modern AI systems are only as powerful as the data pipelines behind them. We build cloud-native AWS data engineering and machine learning pipelines that continuously collect, process, transform, train, and operationalize data at scale — enabling faster analytics, intelligent automation, and production-ready AI systems
AWS Services:
Amazon S3
AWS Glue
Amazon EMR
Amazon Kinesis
Amazon SageMaker
AWS Lambda
Amazon Redshift
Amazon Step Functions
Features:
- End-to-End Data Automation: Automate ingestion, transformation, validation, and delivery of large-scale data workflows
- Production-Ready MLOps Pipelines: Streamline model training, deployment, monitoring, and retraining processes
- Real-Time Data Processing: Enable instant analytics and AI decision-making with streaming data architectures
- Scalable AI Infrastructure: Build resilient cloud-native environments optimized for machine learning operations